ML/Recommendation Engine using BDB Predictive Workbench
Case Study of Recommendation Engine
Our Client is a food franchise company that delivers meals to kids and families whereever they learn and play. Each kitchen is an independently owned and operated franchise, managed by a local business person who manages the production and distribution of nutritious meals for children and families within their community.
To suggest user from a pool of products while ordering, we created a recommendation engine that will take feedback about a product from other customers and suggest the most relevant product that suites the customers.
Create, train and test the model
To create recommendation Engine, we have used BizViz Predictive Analytics which is a data scientist work bench with R, Python, Spark capabilities. By using this, we can train different machine learning models and compare those models on basis of accuracy and various other parameters with test data. If the model accuracy is good enough we can deploy the model on top of actual data which will give you the recommendation.
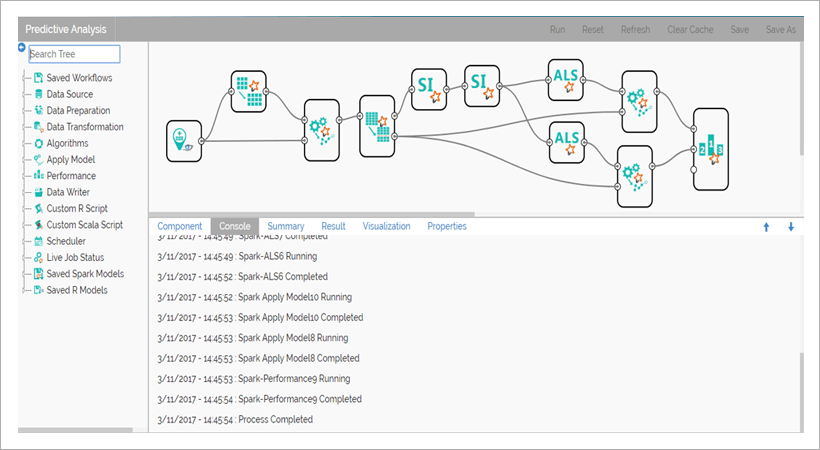
Since our client is having very vast historical data and transaction frequency is very high and the performance of the model should be checked periodically we had to move to a distributed frame work yet which supports the machine learning algorithms. The BizViz Predictive Analytics is the only tool which is integrated with Apache Spark 2.1.0, Machine Learning Algorithms, Pipeline Concept, Train, test and validation of models, deployment of models and monitoring model performance.
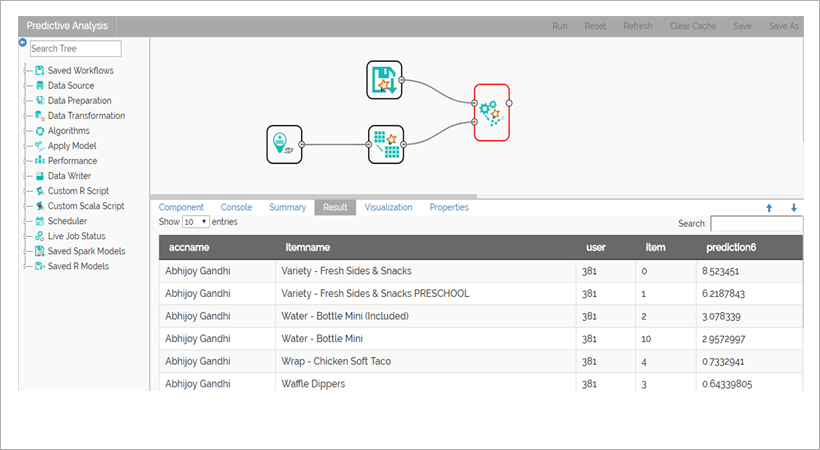
Apply the model on new data for predictions
Since Spark is a distributed compute engine we used Cassandra to store the entire franchise data. To train the model, we retrieved customer name, product subcategory and product name. Major issue with the customer rating is due to missing data. We have used grouping methodology to overcome the rating issue where we used Spark SQL Transformer . To train the model we had to randomly separate the data using Split Data. Entire data is in string format and Spark ALS will only support numerical data, So we used String Indexer to cast string column to numerical column. After converting the data to numerical, we pushed the data to different Spark ALS models. With the help of Spark Performance Component we identified the model which is giving the least Root Mean Squared Error. With Spark Pipeline, we had saved the String Indexer models along with the most suitable ALS model, so that the columns which is coming in String, will be converted to numeric. Entire model gets saved in HDFS and the model made as a service for each user model to start predicting the recommendations
The above-mentioned process is just one way to represent your data via Machine Learning and we get this done through our BDB Predictive Workbench. For more details and a live demo on BDB Machine Learning/Recommendation Engine, contact us at sales@bdb.ai